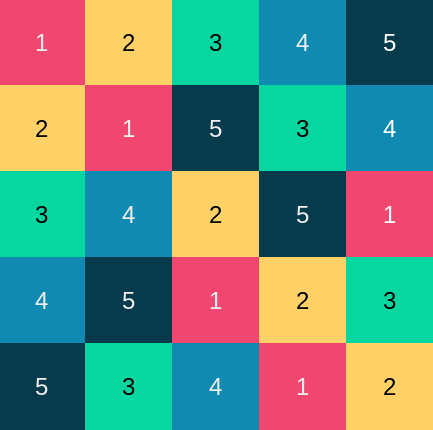
A Latin square is an n × n grid with a number from 1 to n in each cell, such that no number appears twice in a row or twice in a column.
It’s not obvious that Latin squares exist for all n, but they do, and in fact there are a lot of them. The exact number is known only for n ≤ 11. See [1] for the known values. There are upper and lower bounds for all n, and this post will look at how good the bounds are.
A particularly simple result is that number of Latin squares of size n is bounded below by the superfactorial of n [2]. That is, if Ln is the number of Latin squares of size n and the superfactorial of n is defined by
S(n) = 1! × 2! × 3! × … × n!
then
Ln ≥ S(n).
A reduced Latin square is a Latin square in which the elements of the first row and first column are in numerical order. The image at the top of the post is a reduced Latin square. If Rn is the number of reduced Latin squares of size n then
Ln = n! (n − 1)! Rn
and so we can divide the lower bound on Sn by n! (n − 1)! to get a lower bound on Rn:
Rn ≥ S(n − 2).
Ronald Alter [2] gives the following upper bound on Rn:
Here’s now the lower bound, exact value, and upper bound compare for n up to 6.
The numbers get very big for larger n. so let’s switch over to a log scale.
Here’s a plot corresponding to the logarithms of the values above, including all known values of Rn.
The lower and upper bounds are remarkably symmetric about the exact value, which suggests that their average would make a good estimate. Let’s look at a plot.
Indeed, the average of the logs of the bounds is very close to the log of the actual value. This says the number of reduced Latin squares of size n is approximately the geometric mean of its upper and lower bounds, at least for n up to 11.
We can factor S(n-2) out of the upper bound on Rn when computing the geometric mean, and this gives us the approximation
Since we have two bases for the vector space of polynomials, we can ask about the matrices that represent the change of basis from one to the other, and here’s where we see an interesting connection.
The entries of these matrices are numbers that come up in other applications, namely the Stirling numbers. You can think of Stirling numbers as variations on binomial coefficients. More on Stirling numbers here.
In summation notation, we have
where the S1 are the (signed) Stirling numbers of the 1st kind, and the S2 are the Stirling numbers of the 2nd kind.
(There are two conventions for defining Stirling numbers of the 1st kind, differing by a factor of (−1)n-k.)
Matrix form
This means the (i, j)th element of matrix representing the change of basis from the power basis to the falling power basis is S1(i, j) and the (i, j)th entry of the matrix for the opposite change of basis is S2(i, j). These are lower triangular matrices because S1(i, j) and S2(i, j) are zero for j > i.
These are infinite matrices since there’s no limit to the degree of a polynomial. But if we limit our attention to polynomials of degree less than m, we take the upper left m by m submatrix of the infinite matrix. For example, if we look at polynomials of degree 4 or less, we have
to convert from powers to falling powers, and
going from falling powers to powers.
Incidentally, if we filled a matrix with unsigned Stirling numbers of the 1st kind, we would have the change of basis matrix going from the power basis to rising powers defined by
It may be hard to see, but there’s a bar on top of the exponent n for rising powers whereas before we had a bar under the n for falling powers.
In The Big Bang Theory, Sheldon Cooper explains an extension of the game Rock, Paper, Scissors by introducing two more possibilities, Lizard and Spock, so the game becomes Rock, Paper, Scissors, Lizard, Spock. Sam Kass and Karen Bryla invented the game before it became widely known via the television show.
The diagram below summarizes the rules:
Alternative rules
Imagine yourself in the position of Sam Kass and Karen Bryla designing the game. You first try adding one extra move, but it turns out that’s not possible.
The main property of Rock, Paper, Scissors is that no player has a winning strategy. That implies you can only add an even number of extra moves, keeping the total number of moves odd. That way, for every move one player makes, the other player has an equal number of winning and losing moves. Otherwise some moves would be better and others worse. So you can’t add just one move, say Lizard. You have to add two (or four, or six, …).
How many ways could you assign rules to an extension of Rock, Paper, Scissors adding two more moves?
Number the possible moves 1 through 5. We will make a table of which moves beat which, with +1 in the (i, k) position if move i beats move j and -1 if j beats i. There will be zeros on the diagonal since it’s a tie if both players make the same move.
Let’s start with the original Rock, Paper, Scissors. In order for this game to not have a winning strategy, the table must be filled in as below, with the only option being to set a = 1 or a = -1.
|---+----+----+----|
| | 1 | 2 | 3 |
|---+----+----+----|
| 1 | 0 | a | -a |
|---+----+----+----|
| 2 | -a | 0 | a |
|---+----+----+----|
| 3 | a | -a | 0 |
|---+----+----+----|
If 1, 2, and 3 correspond to Rock, Paper, and Scissors, then a = 1 according to the usual rules, but we’ll allow the possibility that the usual rules are reversed. (If you don’t like that, just set a = 1).
Next we fill in the rest of the moves. The table must be skew-symmetric, i.e. the (i, j) element must be the negative of the (j, i) element, because if (i, j) is a winning move then (j, i) is a losing move and vice versa. Also, the rows and columns must sum to zero. Together these requirements greatly reduce the number of possibilities.
|---+----+----+----+----+----|
| | 1 | 2 | 3 | 4 | 5 |
|---+----+----+----+----+----|
| 1 | 0 | a | -a | b | -b |
|---+----+----+----+----+----|
| 2 | -a | 0 | a | c | -c |
|---+----+----+----+----+----|
| 3 | a | -a | 0 | d | -d |
|---+----+----+----+----+----|
| 4 | -b | -c | -d | 0 | d |
|---+----+----+----+----+----|
| 5 | b | c | d | -d | 0 |
|---+----+----+----+----+----|
The values of a, b, and c may each be chosen independently to be 1 or -1. If b + c = 0, then d can be chosen freely. Otherwise b and c have the same sign, and d must have the opposite sign. So all together there are 12 possibilities (6 if you insist a = 1). These are listed below.
The version of the rules used on The Big Bang Theory corresponds to the second row of the table above: a = b = d = 1 and c = -1.
Simpler solution
Here’s another way to count the number of possible designs. Suppose we start with tradition Rock, Paper, Scissors, corresponding to a = 1 in the notation above. Now let’s add the rules for Lizard. We can pick any two things from {Rock, Paper, Scissors, Spock} and say that Lizard beats them, and then the other two things must beat Lizard. There are 6 ways to choose 2 things from a set of 4.
Once we’ve decided the rules for Lizard, we have no choice regarding Spock. Spock’s rules must be the opposite of Lizard’s rules in order to balance everything out. If we decide Lizard beats Rock, for example, then Rock must beat Spock so two things beat Rock and Rock beats two things.
If we’re willing to consider reversing the usual rules of Rock, Paper, Scissors, i.e. setting a = -1, then there are 6 more possibilities, for a total of 12.
Adding two more moves
By the way, we can see from the approach above how to add more moves. If we wanted to add Stephen Hawking and Velociraptor to our game, then we have 20 choices: we choose 3 things out of 6 for Hawking to beat, and the rest of the rules are determined by these choices. Velociraptor has to be the anti-Hawking. If we decide that Hawking beats Paper, Lizard, and Spock, then we’d get the rules in the diagram below.
Fair subsets
You might want to design the game so that for any subset of three moves you have a game with no winning strategy. Here’s an example why. If the subset (1 , 2, 4) is a fair game, then a = c. But if the subset (2, 3, 4) is a fair game, then a = −c. So one of the two games must have a winning strategy.
Graphing the rules
The first graph above was made with GraphVis using the code below.
Here are three things about dominoes, two easy and one more advanced.
Counting
First, how many pieces are there in a set of dominoes? A domino corresponds to an unordered pair of numbers from 0 to n. The most popular form has n = 6, but there are variations with other values of n. You can show that the number of dominoes is
This is because there are n+1 possible numbers (since blanks are a possibility) and each one is either a double or not. The number of ways to choose two distinct numbers is the binomial coefficient and the number of doubles is n+1.
Another way to look at this is that we are selecting two things from a set of n+1 things with replacement and so the number of possibilities is
where the symbol on the left is Stanley’s symbol for selection with replacement.
In any case, there are 28 dominoes when n = 6, 55 when n = 9, and 91 when n = 12.
Magic squares
There are a couple ways to make a magic square of sorts from a set of dominoes. To read more about this, see this post.
Tiling
How many ways can you cover an m by n chess board with dominoes? The answer turns out to be
Stirling numbers are something like binomial coefficients. They come in two varieties, imaginatively called the first kind and second kind. Unfortunately it is the second kind that are simpler to describe and that come up more often in applications, so we’ll start there.
Stirling numbers of the second kind
The Stirling number of the second kind
counts the number of ways to partition a set of n elements into k non-empty subsets. The notation on the left is easier to use inline, and the subscript reminds us that we’re talking about Stirling numbers of the second kind. The notation on the right suggests that we’re dealing with something analogous to binomial coefficients, and the curly braces suggest this thing might have something to do with counting sets.
Since the nth Bell number counts the total number of ways to partition a set of n elements into any number of non-empty subsets, we have
Another connection to Bell is that S2(n, k) is the sum of the coefficients in the partial exponential Bell polynomialBn, k.
Stirling numbers of the first kind
The Stirling numbers of the first kind
count how many ways to partition a set into cycles rather than subsets. A cycle is a sort of ordered subset. The order of elements matters, but only a circular way. A cycle of size k is a way to place k items evenly around a circle, where two cycles are considered the same if you can rotate one into the other. So, for example, [1, 2, 3] and [2, 3, 1] represent the same cycle, but [1, 2, 3] and [1, 3, 2] represent different cycles.
Since a set with at least three elements can be arranged into multiple cycles, Stirling numbers of the first kind are greater than or equal to Stirling numbers of the second kind, given the same arguments.
Addition identities
We started out by saying Stirling numbers were like binomial coefficients, and here we show that they satisfy addition identities similar to binomial coefficients.
For binomial coefficients we have
To see this, imagine we start with the set of the numbers 1 through n. How many ways can we select a subset of k items? We have selections that exclude the number 1 and selections that include the number 1. These correspond to the two terms on the right side of the identity.
The analogous identities for Stirling numbers are
The combinatorial proofs of these identities are similar to the argument above for binomial coefficients. If you want to partition the numbers 1 through n into k subsets (or cycles), either 1 is in a subset (cycle) by itself or not.
More general arguments
Everything above has implicitly assumed n and k were positive, or at least non-negative, numbers. Let’s look first at how we might handle zero arguments, then negative arguments.
It works out best if we define S1(0, k) and S2(0, k) to be 1 if k is 0 and zero otherwise. Also we define S1(n, 0) and S2(n, 0) to be 1 if n is 0 and zero otherwise. (See Concrete Mathematics.)
When either n or k is zero the combinatoric interpretation is strained. If we let either be negative, there is no combinatorial interpretation, though it can still be useful to consider negative arguments, much like one does with binomial coefficients.
We can take the addition theorems above, which are theorems for non-negative arguments, and treat them as definitions for negative arguments. When we do, we get the following beautiful dual relationship between Stirling numbers of the first and second kinds:
The nth Bell number is the number of ways to partition a set of n labeled items. It’s also equal to the following sum.
You may have to look at that sum twice to see it correctly. It looks a lot like the sum for en except the roles of k and n are reversed in the numerator.
The sum reminded me of the equation
that I blogged about a few weeks ago. It’s correct, but you may have to stare at it a little while to see why.
Incidentally, the nth Bell number is the nth moment of a Poisson random variable with mean 1.
There’s also a connection with Bell polynomials. The nth Bell number is the sum of the coefficients of the nth complete Bell polynomial. The nth Bell polynomial is sum over k of the partial exponential Bell polynomials Bn,k. The partial (exponential) Bell polynomials are defined here.
Computing Bell numbers
You can compute Bell numbers in Python with sympy.bell and in Mathematical with BellB. You can compute Bell numbers by hand, or write your own function in a language that doesn’t provide one, with the recursion relation B0 = 1 and
for n > 0. Bell numbers grow very quickly, faster than exponential, so you’ll need extended precision integers if you want to compute very many Bell numbers.
For theoretical purposes, it is sometimes helpful to work with the exponential generating function of the Bell numbers. The nth Bell number is n! times the coefficient of xn in exp(exp(x) − 1).
An impractical but amusing way to compute Bell numbers would be via simulation, finding the expected value of nth powers of random draws from a Poisson distribution with mean 1.
Most basic combinatorial problems can be solved in terms of multiplication, permutations, and combinations. The next step beyond the basics, in my experience, is counting selections with replacement. Often when I run into a problem that is not quite transparent, it boils down to this.
Examples of selection with replacement
Here are three problems that reduce to counting selections with replacement.
Looking ahead in an experiment
For example, suppose you’re running an experiment in which you randomize to n different treatments and you want to know how many ways the next k subjects can be assigned to treatments. So if you had treatments A, B, and C, and five subjects, you could assign all five to A, or four to A and one to B, etc. for a total of 21 possibilities. Your choosing 5 things from a set of 3, with replacement because you can (and will) assign the same treatment more than once.
Partial derivatives
For another example, if you’re taking the kth order partial derivatives of a function of n variables, you’re choosing k things (variables to differentiate with respect to) from a set of n (the variables). Equality of mixed partials for smooth functions says that all that matters is how many times you differentiate with respect to each variable. Order doesn’t matter: differentiating with respect to x and then with respect to y gives the same result as taking the derivatives in the opposite order, as long as the function you’re differentiating has enough derivatives. I wrote about this example here.
Sums over even terms
I recently had an expression come up that required summing over n distinct variables, each with a non-negative even value, and summing to 2k. How many ways can that be done? As many as dividing all the variable values in half and asking that they sum to k. Here the thing being chosen the variable, and since the indexes sum to k, I have a total of k choices to make, with replacement since I can chose a variable more than once. So again I’m choosing k things with replacement from a set of size n.
Formula
I wrote up a set of notes on sampling with replacement that I won’t duplicate here, but in a nutshell:
The symbol on the left is Richard Stanley’s suggested notation for the number of ways to select k things with replacement from a set of size n. It turns out that this equals the expression on the right side. The derivation isn’t too long, but it’s not completely obvious either. See the aforementioned notes for details.
I started by saying basic combinatorial problems can be reduced to multiplication, permutations, and combinations. Sampling with replacement can be reduced to a combination, the right side of the equation above, but with non-obvious arguments. Hence the need to introduce a new symbol, the one on the right, that maps directly to problem statements.
Enumerating possibilities
Sometimes you just need to count how many ways one can select k things with replacement from a set of size n. But often you need to actually enumerate the possibilities, say to loop over them in software.
In conducting a clinical trial, you may want to enumerate all the ways pending data could turn out. If you’re going to act the same way, no matter how the pending data work out, there’s no need to wait for the missing data before proceeding. This is something I did many times when I worked at MD Anderson Cancer Center.
When you evaluate a multivariate Taylor series, you need to carry out a sum that has a term for corresponding to each partial derivative. You could naively sum over all possible derivatives, not taking into account equality of mixed partials, but that could be very inefficient, as described here.
The example above summing over even partitions of an even number also comes out of a problem with multivariate Taylor series, one in which odd terms drop out by symmetry.
To find algorithms for enumerating selections with replacement, see Knuth’s TAOCP, volume 4, Fascicle 3.
As a student, one of the things that seemed curious to me about power series was that a function might have a simple power series, but its inverse could be much more complicated. For example, the coefficients in the series for arctangent have a very simple pattern
but the coefficients in the series for tangent are mysterious.
There’s no obvious pattern to the coefficients. It is possible to write the sum in closed form, but this requires introducing the Bernoulli numbers which are only slightly less mysterious than the power series for tangent.
To a calculus student, this is bad news: a simple, familiar function has a complicated power series. But this is good news for combinatorics. Reading the equation from right to left, it says a complicated sequence has a simple generating function!
Computing the coefficients
The example above suggests that inverting a power series, i.e. starting with the power series for a function and computing the power series for its inverse, is going to be complicated. We introduce exponential Bell polynomials to encapsulate some of the complexity, analogous to introducing Bernoulli numbers above.
Assume the function we want to invert, f(x), satisfies f(0) = 0 and its derivative satisfies f‘(0) ≠ 0. Assume f and its inverse g have the series representations
and
Note that this isn’t the power series per se. The coefficients here are k! times the ordinary power series coefficients. (Compare with ordinary and exponential generating functions explained here.)
Then you can compute the series coefficients for g from the coefficients for f as follows. We have g1 = 1/f1 (things start out easy!) and for n ≥ 2,
where the B‘s are exponential Bell polynomials,
and
is the kth rising power of n. (More on rising and falling powers here.)
Example
Let’s do an example in Python. Suppose we want a series for the inverse of the gamma function near 2. The equations above assume we’re working in a neighborhood of 0 and that our function is 0 at 0. So we will invert the series for f(x) = Γ(x+2) − 1 and then adjust the result to find the inverse of Γ(x).
import numpy as np
from scipy.special import gamma
from sympy import factorial, bell
def rising_power(a, k):
return gamma(a+k)/gamma(a)
# Taylor series coefficients for gamma centered at 2
gamma_taylor_coeff = [
1.00000000000000,
0.42278433509846,
0.41184033042643,
0.08157691924708,
0.07424901075351,
-0.0002669820687,
0.01115404571813,
-0.0028526458211,
0.00210393334069,
-0.0009195738388,
0.00049038845082,
]
N = len(gamma_taylor_coeff)
f_exp_coeff = np.zeros(N)
for i in range(1, N):
f_exp_coeff[i] = gamma_taylor_coeff[i]*factorial(i)
# Verify the theoretical requirements on f
assert( f_exp_coeff[0] == 0 )
assert( f_exp_coeff[1] != 0 )
f_hat = np.zeros(N-1)
for k in range(1, N-1):
f_hat[k] = f_exp_coeff[k+1] / ((k+1)*f_exp_coeff[1])
g_exp_coeff = np.zeros(N)
g_exp_coeff[1] = 1/f_exp_coeff[1]
for n in range(2, N):
s = 0
for k in range(1, n):
# Note that the last argument to bell must be a list,
# and not a NumPy array.
b = bell(n-1, k, list(f_hat[1:(n-k+1)]))
s += (-1)**k * rising_power(n, k) * b
g_exp_coeff[n] = s / f_exp_coeff[1]**n
def g(x):
return sum(
x**i * g_exp_coeff[i] / factorial(i) for i in range(1, N)
)
def gamma_inverse(x):
return 2. + g(x-1.)
# Verify you end up where you started when you do a round trip
for x in [1.9, 2.0, 2.1]:
print( gamma_inverse(gamma(x)) )
Bell polynomials come up naturally in a variety of contexts: combinatorics, analysis, statistics, etc. Unfortunately, the variations on Bell polynomials are confusingly named.
Analogy with differential equations
There are Bell polynomials of one variable and Bell polynomials of several variables. The latter are sometimes called “partial” Bell polynomials. In differential equations, “ordinary” means univariate (ODEs) and “partial” means multivariate (PDEs). So if “partial” Bell polynomials are the multivariate form, you might assume that “ordinary” Bell polynomials are the univariate form. Unfortunately that’s not the case.
It seems that the “partial” in the context of Bell polynomials was taken from differential equations, but the term “ordinary” was not. Ordinary and partial are not opposites in the context of Bell polynomials. A Bell polynomial can be ordinary and partial!
Analogy with generating functions
“Ordinary” in this context is the opposite of “exponential,” not the opposite of “partial.” The analogy is with generating functions, not differential equations. The ordinary generating function of a sequence multiplies the nth term by xn and sums. The exponential generating function of a sequence multiplies the nth term by xn/n! and sums. For example, the ordinary generating function for the Fibonacci numbers is
while the exponential generating function is
where
The definitions of exponential and ordinary Bell polynomials are given below, but the difference between the two that I wish to point out is that the former divides the kth polynomial argument by k! while the latter does not. They also differ by a scaling factor. The exponential form of Bn,k has a factor of n! where the ordinary form has a factor of k!.
“Ordinary” as a technical term
Based on the colloquial meaning of “ordinary” you might assume that it is the default. And indeed that is the case with generating functions. Without further qualification, generating function means ordinary generating function. You’ll primarily see explicit references to ordinary generating functions in a context where it’s necessary to distinguish them from some other kind of generating function. Usually the word “ordinary” will be written in parentheses to emphasize that an otherwise implicit assumption is being made explicit. In short, “ordinary” and “customary” correspond in the context of generating functions.
But in the context of Bell polynomials, it seems that the exponential form is more customary. At least in some sources, an unqualified reference to Bell polynomials refers to the exponential variety. That’s the case in SymPy where the function bell() implements exponential Bell polynomials and there is no function to compute ordinary Bell polynomials.
Definitions
Now for the actual definitions. We can make our definitions more concise if we first define multi-index notation. A multi-index
is a set of n non-negative integers. The norm of a multi-index is defined by
and the factorial of a multi-index is defined by
If x = (x1, x2, …, xn) is an n-tuple of real numbers then x raised to the power of a multi-index α is defined by
The ordinary Bell polynomialBn,k is
where x is a (n – k +1)-tuple and α ranges over all multi-indices subject to two constraints: the norm of α is k and
The exponential Bell polynomials can then be defined in terms of the ordinary bell polynomials by
This post relates moment generating functions to the Laplace transform and to exponential generating functions. It also brings in connections to the z-transform and the Fourier transform.
Thanks to Brian Borchers who suggested the subject of this post in a comment on a previous post on transforms and convolutions.
Moment generating functions
The moment generating function (MGF) of a random variable X is defined as the expected value of exp(tX). By the so-called rule of the unconscious statistician we have
where fX is the probability density function of the random variable X. The function MX is called the moment generating function of X because it’s nth derivative, evaluated at 0, gives the nth moment of X, i.e. the expected value of Xn.
Laplace transforms
If we flip the sign on t in the integral above, we have the two-sided Laplace transform of fX. That is, the moment generating function of X at t is the two-sided Laplace transform of fX at −t. If the density function is zero for negative values, then the two-sided Laplace transform reduces to the more common (one-sided) Laplace transform.
Exponential generating functions
Since the derivatives of MX at zero are the moments of X, the power series for MX is the exponential generating function for the moments. We have
where mn is the nth moment of X.
Other generating functions
This terminology needs a little explanation since we’re using “generating function” two or three different ways. The “moment generating function” is the function defined above and only appears in probability. In combinatorics, the (ordinary) generating function of a sequence is the power series whose coefficient of xn is the nth term of the sequence. The exponential generating function is similar, except that each term is divided by n!. This is called the exponential generating series because it looks like the power series for the exponential function. Indeed, the exponential function is the exponential generating function for the sequence of all 1’s.
The equation above shows that MX is the exponential generating function for mn and the ordinary generating function for mn/n!.
If a random variable Y is defined on the integers, then the (ordinary) generating function for the sequence Prob(Y = n) is called, naturally enough, the probability generating function for Y.
The z-transform of a sequence, common in electrical engineering, is the (ordinary) generating function of the sequence, but with x replaced with 1/z.
Characteristic functions
The characteristic function of a random variable is a variation on the moment generating function. Rather than use the expected value of tX, it uses the expected value of itX. This means the characteristic function of a random variable is the Fourier transform of its density function.
Characteristic functions are easier to work with than moment generating functions. We haven’t talked about when moment generating functions exist, but it’s clear from the integral above that the right tail of the density has to go to zero faster than e−x, which isn’t the case for fat-tailed distributions. That’s not a problem for the characteristic function because the Fourier transform exists for any density function. This is another example of how complex variables simplify problems.

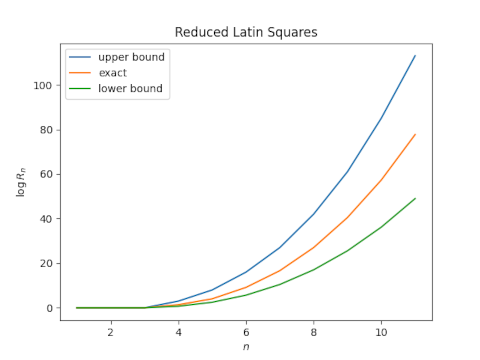
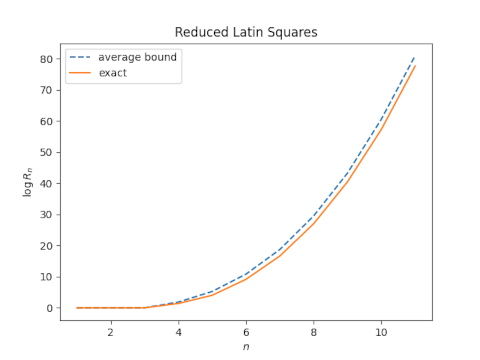 Indeed, the average of the logs of the bounds is very close to the log of the actual value. This says the number of reduced Latin squares of size n is approximately the geometric mean of its upper and lower bounds, at least for n up to 11.
Indeed, the average of the logs of the bounds is very close to the log of the actual value. This says the number of reduced Latin squares of size n is approximately the geometric mean of its upper and lower bounds, at least for n up to 11.