This post looks at how to partition complexity between definitions and theorems, and why it’s useful to be able to partition things more than one way.
Quadratic equations
Imagine the following dialog in an algebra class.
“Quadratic equations always have two roots.”
“But what about (x − 5)² = 0. That just has one root, x = 5.”
“Well, the 5 counts twice.”
Bézout’s theorem
Here’s a more advanced variation on the same theme.
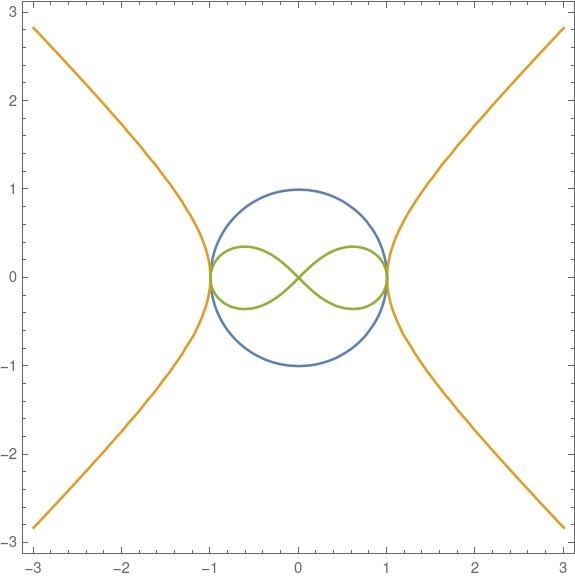
“A curve of degree m and a curve of degree n intersect in mn places. That’s Bézout’s theorem.”
“What about the parabola y = (x − 5)² and the line y = 0. They intersect at one point, not two points.”
“The point of intersection has multiplicity two.”
“That sounds familiar. I think we talked about that before.”
“What about the parabola y = x² + 1 and the line y = 0. They don’t intersect at all.”
“You have to look at complex numbers. They intersect at x = i and x = −i.”
“Oh, OK. But what about the line y = 5 and the line y = 6. They don’t intersect, even for complex numbers.”
“They intersect at the point at infinity.”
In order to make the statement of Bézout’s theorem simple you have to establish a context that depends on complex definitions. Technically, you have to work in complex projective space.
Definitions and theorems
Michael Spivak says in the preface to his book Calculus on Manifolds
… the proof of [Stokes’] theorem is … an utter triviality. On the other hand, even the statement of this triviality cannot be understood without a horde of definitions … There are good reasons why the theorems should all be easy and the definitions hard.
There are good reasons, for the mathematician, to make the theorems easy and the definitions hard. But for students, there may be good reasons to do the opposite.
Here math faces a tension that programming languages (and spoken languages) face: how to strike a balance between the needs of novices and the needs of experts.
In my opinion, math should be taught bottom-up, starting with simple definitions and hard theorems, valuing transparency over elegance. Then, motivated by the complication of doing things the naive way, you go back and say “In light of what we now know, let’s go back and define things differently.”
It’s tempting to think you can save a lot of time by starting with the abstract final form of a theory rather than working up to it. While that’s logically true, it’s not pedagogically true. A few people with an unusually high abstraction tolerance can learn this way, accepting definitions without motivation or examples, but not many. And the people who do learn this way may have a hard time applying what they learn.
Applications
Application requires moving up and down levels of abstraction, generalizing and particularizing. And particularizing is harder than it sounds. This lesson was etched into my brain by an incident I relate here. Generalization can be formulaic, but recognizing specific instances of more general patterns often requires a flash of insight.
Spivak said there are good reasons why the theorems should all be easy and the definitions hard. But I’d add there are also good reasons to remember how things were formulated with hard theorems and easy definitions.
It’s good, for example, to understand analysis at a high level as in Spivak’s book, with all the machinery of differential forms etc. and also be able to swoop down and grind out a problem like a calculus student.
Going back to Bézout’s theorem, suppose you need to find real solutions a system of equations that amounts to finding where a quadratic and cubic curve intersect. You have a concrete problem, then you move up to the abstract setting of Bézout’s theorem learn that there are at most six solutions. Then you go back down to the real world (literally, as in real numbers) and find two solutions. Are there any more solutions that you’ve overlooked? You zoom back up to the abstract world of Bézout’s theorem, and find four more by considering multiplicities, infinities, and complex solutions. Then you go back down to the real world, satisfied that you’ve found all the real solutions.
A pure mathematician might climb a mountain of abstraction and spend the rest of his career there, but applied mathematicians have to go up and down the mountain routinely.