The previous post took a mathematical look at the National Football League. This post will do the same for Major League Baseball.
Like the NFL, MLB teams are organized into a nice tree structure, though the MLB tree is a little more complicated. There are 32 NFL teams organized into a complete binary tree, with a couple levels collapsed. There are 30 MLB teams, so the tree structure has to be a bit different.
MLB has leagues rather than conferences, but the top-level division is into American and Nation as with the NFL. So the top division is into the American League and the National League.
And as with football, the next level of the hierarchy is divisions. But baseball has three divisions—East, Central, and West—in contrast to four in football.
Each division has five baseball teams, while each football division has four teams.
Here’s the basic tree structure.
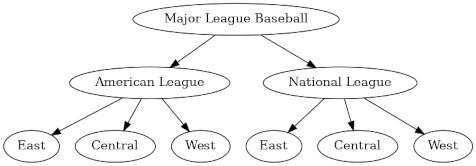
Under each division are five teams. Here’s a PDF with the full graph including teams.
Geography
How do the division names correspond to actual geography?
Within each league, the Central teams are to the west of the East teams and to the east of the West teams, with one exception: in the National League, the Pittsburgh Pirates are a Central division team, but they are east of the Atlanta Braves and Miami Marlins in the East division. But essentially the East, Central, and West divisions do correspond to geographic east, center, and west, within a league.
Numbering
We can’t number baseball teams as elegantly as the previous post numbered football teams. We’d need a mixed-base number. The leading digit would be binary, the next digit base 3, and the final digit base 5.
We could number the teams so that you could tell the league and division of the team by looking at the remainders when the number is divided by 2 and 3, and each team is unique mod 5. By the Chinese Remainder Theorem, we can solve the system of congruence equations mod 30 that specify the value of a number mod 2, mod 3, and mod 5.
If we number the teams as follows, then even numbered teams are in the American League and odd numbered teams are in the National League. When the numbers are divided by 3, those with remainder 0 are in an Eastern division, those with remainder 1 are in a Central division, and those with remainder 2 are in a Western division. Teams within the same league and division have unique remainders by 5.
- Cincinnati Reds
- Oakland Athletics
- Philadelphia Phillies
- Minnesota Twins
- Arizona Diamondbacks
- Boston Red Sox
- Milwaukee Brewers
- Seattle Mariners
- Washington Nationals
- Chicago Whitesocks
- Colorado Rockies
- New York Yankees
- Pittsburgh Pirates
- Texas Rangers
- Atlanta Braves
- Cleveland Guardians
- Los Angeles Dodgers
- Tampa Bay Rays
- St. Louis Cardinals
- Houston Astros
- Miami Marlins
- Detroit Tigers
- San Diego Padres
- Toronto Blue Jays
- Chicago Cubs
- Los Angeles Angels
- New York Mets
- Kansas City Royals
- San Francisco Giants
- Baltimore Orioles




{kind=link}