I keep running into the function
f(z) = (1 − z)/(1 + z).
The most recent examples include applications to radio antennas and mental calculation. More on these applications below.
Involutions
A convenient property of our function f is that it is its own inverse, i.e. f( f(x) ) = x. The technical term for this is that f is an involution.
The first examples of involutions you might see are the maps that take x to −x or 1/x, but or function shows that more complex functions can be involutions as well. It may be the simplest involution that isn’t obviously an involution.
By the way, f is still an involution if we extend it by defining f(−1) = ∞ and f(∞) = −1. More on that in the next section.
Möbius transformations
The function above is an example of a Möbius transformation, a function of the form
(az + b)/(cz + d).
These functions seem very simple, and on the surface they are, but they have a lot of interesting and useful properties.
If you define the image of the singularity at z = −d/c to be ∞ and define the image of ∞ to be a/c, then Möbius transformations are one-to-one mappings of the extended complex plane, the complex numbers plus a point at infinity, onto itself. In fancy language, the Möbius transformations are the holomorphic automorphisms of the Riemann sphere.
More on why the extended complex plane is called a sphere here.
One nice property of Möbius transformations is that they map circles and lines to circles and lines. That is, the image of a circle is either a circle or a line, and the image of a line is either a circle or a line. You can simplify this by saying Möbius transformations map circles to circles, with the understanding that a line is a circle with infinite radius.
Electrical engineering application
Back to our particular Möbius transformation, the function at the top of the post.
I’ve been reading about antennas, and in doing so I ran across the Smith chart. It’s essentially a plot of our function f. It comes up in the context of antennas, and electrical engineering more generally, because our function f maps reflection coefficients to normalized impedance. (I don’t actually understand that sentence yet but I’d like to.)
The Smith chart was introduced as a way of computing normalized impedance graphically. That’s not necessary anymore, but the chart is still used for visualization.
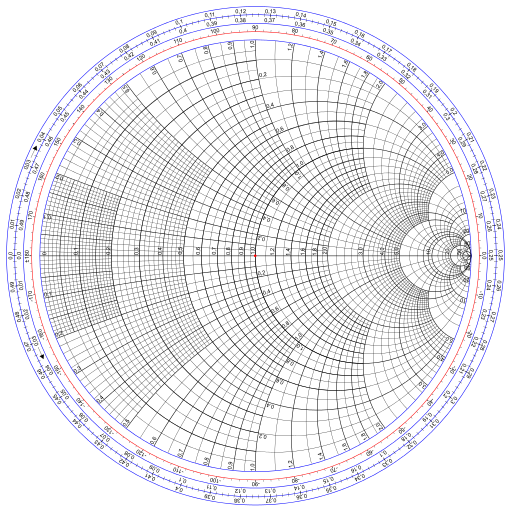
Image Wdwd, CC BY-SA 3.0, via Wikimedia Commons.
Mental calculation
It’s easy to see that
f(a/b) = (b − a)/(b + a)
and since f is an involution,
a/b = f( (b − a)/(b + a) ).
Also, a Taylor series argument shows that for small x,
f(x)n ≈ f(nx).
A terse article [1] bootstraps these two properties into a method for calculating roots. My explanation here is much longer than that of the article.
Suppose you want to mentally compute the 4th root of a/b. Multiply a/b by some number you can easily take the 4th root of until you get a number near 1. Then f of this number is small, and so the approximation above holds.
Bradbury gives the example of finding the 4th root of 15. We know the 4th root of 1/16 is 1/2, so we first try to find the 4th root of 15/16.
(15/16)1/4 = f(1/31)1/4 ≈ f(1/124) = 123/125
and so
151/4 ≈ 2 × 123/125
where the factor of 2 comes from the 4th root of 16. The approximation is correct to four decimal places.
Bradbury also gives the example of computing the cube root of 15. The first step is to multiply by the cube of some fraction in order to get a number near 1. He chooses (2/5)3 = 8/125, and so we start with
15 × 8/125 = 24/25.
Then our calculation is
(24/25)1/3 = f(1/49)1/3 ≈ f(1/147) = 73/74
and so
151/3 ≈ (5/2) × 73/74 = 365/148
which is correct to 5 decimal places.
Update: See applications of this transform to mentally compute logarithms.
[1] Extracting roots by mental methods. Robert John Bradbury, The Mathematical Gazette, Vol. 82, No. 493 (Mar., 1998), p. 76.





{kind=link}