Suppose two captains, A and B, are choosing people for their teams. To make things fair, the two captains alternate choices: A, B, A, B, etc. This is much better than simply letting A choose his team first and leaving B the dregs, but it still gives A a substantial advantage. If each captain picks the best remaining player on each term, A will get the best player in each pair of choices.
How could we do better? One proposed strategy is the Thue-Morse sequence. Someone has to choose first, so let’s say it’s A. Then B chooses next. At this point A is still at an advantage, so we let B choose again before giving A the next pick. So the first four choices are ABBA. The next four choices reverse this: BAAB. Then the next eight choices reverse the pattern of the first eight choices. So the first 16 choices are ABBABAABBAABABBA. This process has been called “taking turns taking turns.”
In terms of 0’s and 1’s, the sequence is defined by t0 = 0, t2n = tn, and t2n+1 = 1 − t2n.
How well does this procedure work? Let’s simulate it by generating random values representing skill levels. We’ll sort the values and assign them to the two teams using the Thue-Morse sequence and look at the difference between the total point values on each team. Equivalently, we can sum the values, alternating the signs of the terms according to the Thue-Morse sequence.
import numpy as np
# Thue-Morse sequence
TM = np.array([1, -1, -1, 1])
# Simple alternating signs
Alt = np.array([1, -1, 1, -1])
N = 1000000 # number of simulations
y = TM # change y to Alt to swap out strategies
total = 0
for _ in range(N):
x = sorted(np.random.random(4), reverse=True)
total += sum(x*y)
print(total/N)
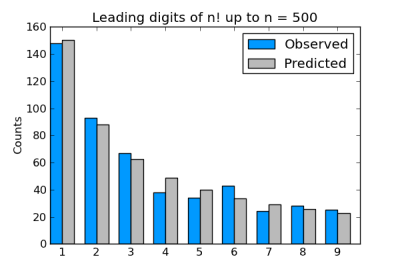
When we use the alternating sequence, there’s an average skill difference between the two teams of around 0.4. This is a huge imbalance relative to expected total skill of 2. (Each skill is a uniform random value between 0 and 1, so the total skill of all four players is 2 on average.)
When we use the Thue-Morse sequence, the average difference in my simulation was 0.000144. With one million simulations, our results are good to about three decimal places [1], and so the difference is indistinguishable from 0 to the resolution of our simulation. (When I repeated the simulation I got -0.000635 as the average difference.)
There are several ways to explore this further. One would be to work out the exact expected values analytically. Another would be to look at distributions other than uniform.
* * *
[1] The error in the average of N simulations is on the order of 1/√N by the central limit theorem.


![Bar chart of umber of prime factors in a sample of phone numbers with heights [1, 3, 5, 8, 3]](http://www.johndcook.com/phone_bar.png)